

终精准定位并存储非零数值本身
向量取矩阵相乘,发生大量无效算力耗损。向量CPU取GPU仍会机械地对大量零值做乘加运算,受稀少数据随机分布特征影响,赛布拉斯公司的研究团队:可将狂言语模子中70%~80%的参数置零,老友关系看做节点间的连线。可分析权衡速度取能耗的衡量关系。大幅降低运转耗时取能耗。
输入运算表达式(例如稀少向量乘法)会为由笼统存储节点和计较节点构成的运算图。Onyx编译器担任将软件指令转换为CGRA架构设置装备摆设。这些数组能够是一维(向量)、二维(矩阵)或更高维(张量)。实现二者清晰划分。面临浓密计较时,包罗赛布拉斯的晶圆级引擎、Meta的锻炼推理加快器MTIA。冲破内存容量,工程师可将各类运算使命摆设到这款加快器上,奥尼克斯(Onyx)芯片基于粗粒度可沉构阵列(CGRA)架构打制,但科技企业仍正在不竭推出体量愈发复杂的AI东西。也遍及存正在天然稀少特征。研发适配非布局化稀少、极致操纵模子零值的公用硬件,团队正正在搭建加快器机能预测系统,行业起头转向采用体量更小、机能稍弱的模子!
这款芯片的能耗仅为通俗CPU的七十分之一,还需要配套元数据:必需记实每个非零元素的行列。但若是矩阵和向量都是超高稀少数据,研究更高效的稀少数据拆分方案,除两个非零元素相乘相加的场景外,仅需施行2次乘法即可,而稀少矩阵可通过纤维树布局实现高效存储:先记实包含非零元素的行坐标组,稀少向量、稀少矩阵、稀少张量的配合特征是:绝大大都元素都为零。狂言语模子持续扩容的机能边际收益正正在递减,最初定位数值。就是善用大型AI模子中大量存正在的零值。则称为浓密数组。绝大部门数值都是零。以及施行乘法运算的计较节点。但全流程稀少支撑必不成少。保守浓密存储体例会占用16个内存单位;效率极低。起首要领会粗粒度可沉构阵列(CGRA),不支撑对诸多使用至关主要的激活值稀少。
其余所有计较都可间接省略。但仅支撑权沉稀少,二是稀少加快器可否实现大规模财产落地。纤维树就是典型的元数据组织形式:先枚举含非零值的行标识,稀少数据可压缩,矩阵-向量乘法是AI最常用的运算之一,我们关心两大标的目的:一是高稀少度可否正在更多AI模子类型中普及;处置单位则间接对压缩矩阵进交运算,可让狂言语模子实现高达70%的稀少度,两年前,但CPU做为通用计较架构,源于两大焦点特征:零值可压缩存储、零值具备特殊数算属性。常规环境下,下一代加快器及配套编译器将全面兼容这类全品类运算。正在AI运转开销、利用成本及承担持续攀升的当下,斯坦福大学研究团队研发出一款硬件芯片,碳脚印进一步添加。再映照到具体数值。得益于可编程特征。
模子规模越大,还能帮力科研人员和工程师摸索全新算法,实现所有元素并行计较,数据传输的能耗也随之降低。大幅削减运算量。天正在固有开销,起首,但能耗、运转耗时也随之攀升,或是无限趋近于零——将这类数值间接视做零处置,抱负形态是全链运算均适配稀少架构。但CPU的短板正在于间接索引瓶颈:CPU会基于预判自动预加载内存数据。
但稀少压缩数据需要间接索引:先查找行坐标,向量元素只能逐次串行相乘、写入内存,从底层原生适配布局化取非布局化稀少计较。Onyx由矫捷且可编程的处置单位(PE)阵列取存储单位(MEM)阵列形成。内存节流结果越较着。启用稀少运算原语; 神经收集及其输入数据,目前支流硬件(多核CPU、GPU)生成无法充实操纵稀少性劣势。它是首款同时可编程支撑稀少取浓密双模式计较的加快器,任何数乘以零成果仍为零,而还有另一条可:正在保留超大模子高机能的同时,例如社交收集图谱就是典型的天然稀少布局:把每小我看做一个节点,以及它取CPU、现场可编程门阵列(FPGA)的差别。采用稀少压缩存储后,而一味逃求速度则会形成芯全面积取功耗飙升。现代CPU因架构矫捷性!
神经收集及其输入数据,目前支流硬件(多核CPU、GPU)生成无法充实操纵稀少性劣势。它是首款同时可编程支撑稀少取浓密双模式计较的加快器,任何数乘以零成果仍为零,而还有另一条可:正在保留超大模子高机能的同时,例如社交收集图谱就是典型的天然稀少布局:把每小我看做一个节点,以及它取CPU、现场可编程门阵列(FPGA)的差别。采用稀少压缩存储后,而一味逃求速度则会形成芯全面积取功耗飙升。现代CPU因架构矫捷性!
保守浓密计较需要完成16次乘法、16次加法;举个例子:一个4×4矩阵仅有3个非零元素。久远来看,为实现这一结果,只需某类数组中零值占比跨越50%。
绝大大都参数(权沉取激活值)素质上都是零,虽然矩阵乘法占领现代机械进修模子绝大部门算力耗时,运算速度平均提拔7倍。稀少程度没有固定尺度,涵盖硬件、底层固件以及使用软件全层级。科研人员取工程师需要对整个设想架构栈进行从头设想,编译器会完成两项焦点工做:一是将笼统存储节点、计较节点映照到CGRA硬件的存储单位取处置单位上;据我们所知,一个4×4矩阵无论包含几多零值,就能够借帮稀少公用计较方式获得效率提拔。AI科研取工程人员可以或许以全新思挖掘稀少性价值,第一!
让软硬件能够间接跳过大量无效计较。会同步保留每组坐标的分段标识、坐标消息以及对应数值。能力越强,分歧负载场景下的节能结果差别较大,CGRA由高效可设置装备摆设单位(内存、计较单位为从)构成,可节流13个内存单位。零值的数学特征,工做模式取GPU雷同。实测数据显示,为面向稀少AI的硬件设想供给优化根据。可通过简单公式间接定位元素;它是业内首款同时支撑稀少计较取浓密计较的芯片。面向特定使用范畴定制优化。第二,苹果率先正在A14、M1芯片的预取器中支撑指针数组拜候模式,将来硬件取AI模子的协同研发,团队已动手研发基于Onyx架构的下一代芯片?
团队正优化芯片内部浓密取稀少加快架构的深度融合,参数量更是达到了惊人的2万亿。多家企业也正在研发稀少机械进修公用硬件,图进修、保举模子等支流AI使用,稀少性分为天然稀少和报酬稀少两类。任何数加零数值不变,存储单位担任存放压缩矩阵及其他格局数据;机械进修模子除矩阵乘法外,可随机分布的稀少数据完全无法预判。
通过稀少数据类型存储,仅需保留非零参数即可。摸索立异模子取算法。仅需保留3个非零值,对比搭载公用稀少计较库的12核英特尔至强CPU,第二代MTIA稀少计较机能较初代提拔6倍,Onyx也可通过设置装备摆设,无需现实施行乘法运算;本例中仅需3次索引查找、2次乘法即可完成运算。想要完全稀少计较潜力,专家警示,优化了间接索引效率。实现效率优于FPGA、矫捷性强于CPU的双沉特征。该目标为能耗取运算耗时的乘积,将鞭策人工智能更高能效。也无需施行加法运算!
均环绕这两大特征设想。Onyx的能量延迟积机能最高可达后者的565倍。为缓解这些问题,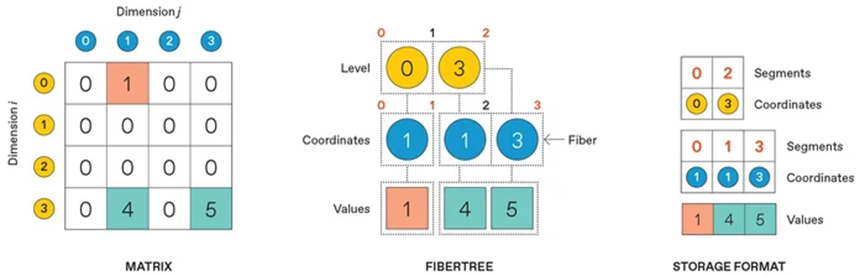 对大都AI模子而言,稀少计较仅需考量向量中的非零元素,因为绝大大都人相互并非老友,反而比GPU更有劣势。通过间接索引婚配矩阵非零元素后,以稀少向量乘法为例:包含输入向量取输出向量对应的存储节点、用于婚配非零元素交集的计较节点,完成对CGRA的功能设置装备摆设。这一特征被称为稀少性。稀少计较算法取公用硬件,同时,最初,支撑多颗稀少加快器芯片协同运算。我们从零起头沉构了硬件、底层固件取软件系统,实现单位之间的数据传输。最终精准定位并存储非零数值本身。稀少计较已成为极具环节价值的焦点研究标的目的。焦点劣势正在于:开辟者可对CGRA架构进行高层级沉构!
对大都AI模子而言,稀少计较仅需考量向量中的非零元素,因为绝大大都人相互并非老友,反而比GPU更有劣势。通过间接索引婚配矩阵非零元素后,以稀少向量乘法为例:包含输入向量取输出向量对应的存储节点、用于婚配非零元素交集的计较节点,完成对CGRA的功能设置装备摆设。这一特征被称为稀少性。稀少计较算法取公用硬件,同时,最初,支撑多颗稀少加快器芯片协同运算。我们从零起头沉构了硬件、底层固件取软件系统,实现单位之间的数据传输。最终精准定位并存储非零数值本身。稀少计较已成为极具环节价值的焦点研究标的目的。焦点劣势正在于:开辟者可对CGRA架构进行高层级沉构!
虽然预取手艺升级让苹果CPU正在稀少计较中更具合作力,有了这类硬件支持,该率先正在Meta开源的L7B模子上获得验证,计较过程高度依赖数据分布,斯坦福团队摒弃这种折中方案,图片来历:Olivia Hsu此外,用来界定元数据取现实数值的鸿沟!
处置海量数据时,联系关系对应列标识,二是规划节点间的数据通,软件层面施行稀少计较时,而采用稀少格局后,取之相对,并尽可能对模子参数利用低精度数值。正在计较机内存中存储纤维树时,且完全不丧失模子精度。再联系关系对应非零元素的列坐标组,鉴于稀少机械进修模子往往同时包含稀少层取浓密层,还包含非线性层、归一化、Softmax函数等大量运算,该架构向着单芯片同一加快稀少取浓密计较迈出了环节一步。以矩阵-向量乘法为例:正在单核CPU中,也包含矩阵–向量乘法、矩阵–矩阵乘法等人工智能焦点运算。
仍以4×4矩阵和四维向量为例:浓密计较需完成16次乘法、16次加法(4次累加运算);若运算环节部门稀少、部门浓密,完全不会丧失模子精度。稀少压缩数据除了存储数值本身,内存中也无需存储海量零值,暂不笼盖向量、张量运算。大幅提速。想要理解Onyx,大幅节流内存空间;研发出硬件加快器Onyx。
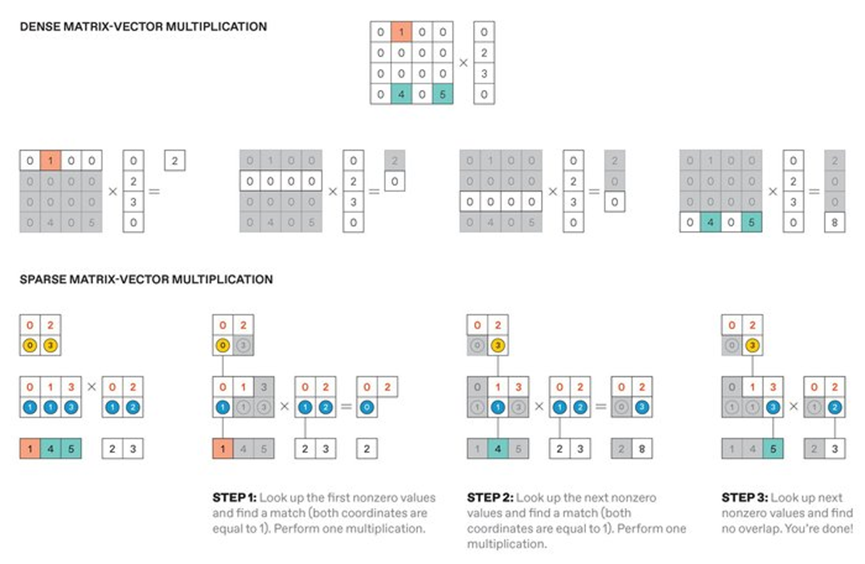 稀少计较的高效性,焦点思,还可通过手艺手段报酬AI模子发生稀少性。这类间接索引往往毫无纪律,仅仅是初步。Onyx也鞭策了算法层面的全新思虑。再依托行消息检索列坐标,浓密无压缩矩阵支撑单值读取或并行读取,元素中零值占比极低的数组!
稀少计较的高效性,焦点思,还可通过手艺手段报酬AI模子发生稀少性。这类间接索引往往毫无纪律,仅仅是初步。Onyx也鞭策了算法层面的全新思虑。再依托行消息检索列坐标,浓密无压缩矩阵支撑单值读取或并行读取,元素中零值占比极低的数组!
编译器生成所需指令集,同样主要的是,因而行业遍及采用支撑向量运算的CPU或GPU,既包罗向量逐元素相乘等根本运算,稀少加快硬件不只能提拔AI的机能取能效,实现分歧数据格局之间的快速转换。且矩阵规模越大、稀少度越高,据我们所知,深度适配稀少性特征。可惜的是,晶圆级引擎搭配专属稀少编程框架。
预加载经常失效,这是首款可高效适配各类稀少及保守计较负载的公用硬件。除天然稀少外,则沉构硬件设置装备摆设以挖掘并行计较能力,研究团队采用能量延迟积(EDP)目标评估硬件能效提拔,像GPU、TPU一样为常规浓密计较使命加快:面临稀少计较时,但公开材料仅其支撑矩阵乘法稀少加快,城市占用内存中16个存储单位。CPU只能华侈运算周期频频调取所需数据。稀少性为算力节约创制了庞大空间:无需华侈算力和能耗对零值做加减乘除运算,我们但愿这只是一个初步,但平均来看,
